 [dutch]Spam sucks. Of het nu in onze e-mail inboxen of weblog comments is, we willen geen zinloze reclame voor troep die we niet nodig hebben. Wij eigenaren van weblogs en websites willen al helemaal niet dat onze thuisbasis op het internet verwordt tot een aanplakplaats voor deze producten, dus we doen er van alles aan om dat te voorkomen. De meeste van deze maatregelen zijn gebaseerd op het meest basale wat we van comment spam weten: het wordt nooit geplaatst door mensen.
[dutch]Spam sucks. Of het nu in onze e-mail inboxen of weblog comments is, we willen geen zinloze reclame voor troep die we niet nodig hebben. Wij eigenaren van weblogs en websites willen al helemaal niet dat onze thuisbasis op het internet verwordt tot een aanplakplaats voor deze producten, dus we doen er van alles aan om dat te voorkomen. De meeste van deze maatregelen zijn gebaseerd op het meest basale wat we van comment spam weten: het wordt nooit geplaatst door mensen.
De meest effectieve manier om comment spam tegen te gaan is tevens de meest simpele: vraag de commenter simpelweg te bewijzen dat hij/zij menselijk is, alvorens enig commentaar toe te staan. De CAPTCHA was geboren: een “Completely Automated Public Turing test to tell Computers and Humans Apart”, waarbij de menselijke gebruiker wordt gevraagd een plaatje te decoderen, waarop een woord of een combinatie van letters en cijfers is afgebeeld; vervormd om automatische tekstherkenning (OCR) te voorkomen.
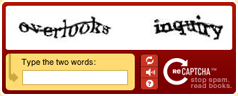 Wereldwijd lossen mensen dagelijks zo’n 60 miljoen van deze CAPTCHA’s op, terwijl organisaties als The Internet Archive hun nek breken over onleesbare woorden bij het digitaliseren van boeken. Het was dan ook een kwestie of tijd voor iemand de simpele optelsom maakte om tot de conclusie te komen dat één plus één twee is. Het resultaat: reCAPTCHA. Door lastig te herkennen woorden uit ingescande boeken van The Internet Archive te gebruiken, in plaats van willekeurig gegenereerde troep, wordt het werk van CAPTCHA-invullers wereldwijd gebundeld en aangewend om te helpen bij het digitaliseren van boeken.
Wereldwijd lossen mensen dagelijks zo’n 60 miljoen van deze CAPTCHA’s op, terwijl organisaties als The Internet Archive hun nek breken over onleesbare woorden bij het digitaliseren van boeken. Het was dan ook een kwestie of tijd voor iemand de simpele optelsom maakte om tot de conclusie te komen dat één plus één twee is. Het resultaat: reCAPTCHA. Door lastig te herkennen woorden uit ingescande boeken van The Internet Archive te gebruiken, in plaats van willekeurig gegenereerde troep, wordt het werk van CAPTCHA-invullers wereldwijd gebundeld en aangewend om te helpen bij het digitaliseren van boeken.
Ik zie echter wel een probleem: het zou onmogelijk zijn om slechts niet-OCR-bare woorden te gebruiken voor verificatie: het systeem zou dan onmogelijk kunnen controleren of de gebruiker het juiste antwoord heeft ingevuld, dat weet het zelf tenslotte niet. reCAPTCHA lost dit op door twee woorden aan te bieden in iedere CAPTCHA, waarvan één reeds bekend is, de andere nog onbekend. De verificatie gebruikt slechts het deel dat reeds bekend is, terwijl het andere deel wordt doorgespeeld aan (in dit geval) The Internet Archive, om hen te helpen het te decoderen. In andere woorden: het systeem dat niet-menselijke commenters moet trakteren op een plaatje dat niet door computers is te herkennen, gebruikt een plaatje dat reeds door een computer is herkend! Als een spammer dus een OCR-systeem gebruikt dat net zo goed is als het syteem dat reCAPTCHA traint, wordt daarmee in één klap waardeloos. Daarnaast zal de spammer waarschijnlijk het onherkenbare deel van elke reCAPTCHA vervuilen met troep, het is tenslotte toch niet nodig voor de verificatie, waardoor het hele project onbruikbaar wordt.
Natuurlijk kan dit scenario worden voorkomen. Het “herkenbare” deel van de reCAPTCHA zou zo recentelijk mogelijk gedecodeerd moeten zijn door mensen en het zou idealiter willekeurig moeten zijn welke van de twee worden in de reCAPTCHA “herkenbaar” en welke “onbekend” is. Ik hoop dat de mensen van reCAPTCHA hier ook aan gedacht hebben.
[/dutch]
[english]Spam sucks. Whether it is in our email inboxes or weblog comments, we don’t want useless messages advertising stuff we don’t need. We owners of weblogs and websites especially don’t want our home sweet home to become the advertising spot for these products, so we take measures to prevent it, almost all of them based on the most basic fact we know about all comment spam: it is never posted by humans.
The most effective way to prevent comment spam is also the most simple: simply ask the commenter to prove he/she is human before allowing any comments to be posted. So the CAPTCHA was born: a “Completely Automated Public Turing test to tell Computers and Humans Apart”, where the human commenter is asked to decode an image representing a word or a combination of letters and digits, garbled to make automatic recognition (OCR) impossible.
Human beings worldwide sort an estimated 60 million of these CAPTCHA’s every day, while organisations like the Internet Archive struggle to digitize badly recognizable books. It was only a matter of time before someone figured out 1+1 equals two. And someone finally did: reCAPTCHA. By using words scanned from books for the Internet Archive for verification, instead of randomly generated garbage, the global effort of solving CAPTCHA’s is channeled and put to good use in aiding the digitizing of books.
However, I do see one problem: it would be impossible to use just the non-OCRable words for verification: the system would not be usable as a verification, since the checking end would not know the correct answer. reCAPTCHA solves this by using two words for each captcha: one of which has been correctly identified, the other yet unknown. The verification only uses the word that has already been identified, while the other part is passed on to (in this case) the Internet Archive to help them in decoding it. In other words: the system that has to challenge non-human commenters with a string computers cannot decode uses a word that has already been decoded by a computer! Assuming a spammer’s OCR-system might ever reach the same level of expertise as the system reCAPTCHA is teaching, any reCAPTCHA instantly becomes worthless. Moreover, the spammer would probably flood the “unknown” part of the captcha with garbage, since it is not needed for the verification anyway, rendering the entire project useless.
Of course this scenario can be prevented. The “reconizable” part of the reCAPTCHA should be as recently decoded by humans as possible and it should ideally be random which of the two words in the reCAPTCHA is the “recognizable” and which is the “unknown”. I hope the guys at reCAPTCHA thought of this.
[/english]






